Канитель — (от франц. cannetille), тонкая металлическая (обычно золотая или серебряная) нить, употребляемая для вышивания (БСЭ)
Статистика по русской лингвистикеЗдесь представлена статистика, собранная во время создания простейшего робота-генератора русских фраз (см. начало сайта) Распределение словНа 12.5Мб русского текста (в основном классическая литература разных авторов), на 142114 разных слов в нём, чаще всего встречается союз «и» — 83575 раз (слова берутся во всех словоформах). И это больше, чем половина! Вторым по частоте встречаемости оказывается предлог «в» — 52124 раз, на третьем месте — частица «не»: 36268 раз.Глагол «сказал» (ед.ч.,3л.) встречается 6566 раз и находится на 28-м месте. А вот слово «да» находится на 36-м месте и встречается 5039 раз, тогда как «нет» — встречается 2948 раз и находится на 53 месте. Остальные слова выбраны достаточно случайно, исходя из предпочтений автора.
Для наглядности картинки взяты те же слова, что и в предыдущем анализе, но по первым местам уже видно, что распределение существенно меняется и 3-е место заняло местоимение «он» (6-е место в распределении всех словоформ), а местоимение «она» находится в данном случае на 10-м месте (18-е место соответственно).
Эти распределения, однако, можно представить более наглядно, а именно: если мы прологарифмируем их по обеим осям, то они, соответственно, станут выглядеть вот так: 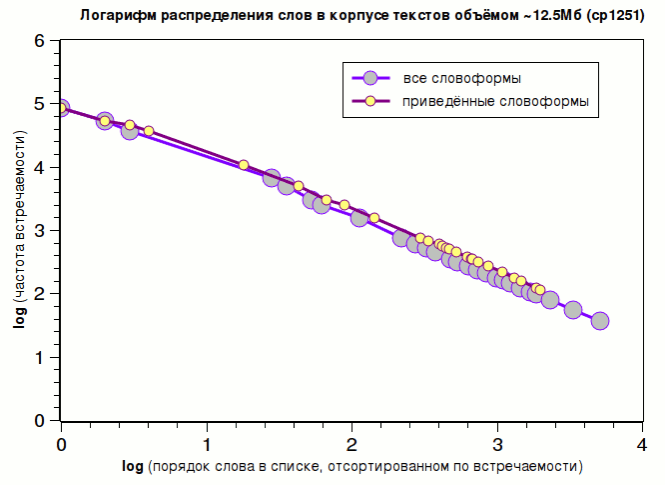 Т.о., мы увидели, что закон распределения слов в тексте на русском языке подчиняется степенной функции, и этот закон можно выразить иначе: вероятность встретить данное слово в русском тексте более, чем k раз, подчиняется степенному закону: P(k) ~ k-γ
В первом случае γ=~1.11, а во втором γ=~1.15 Распределение словоформТеперь интересно посмотреть на распределение словоформ. Например, союзы и предлоги имеют по одной единственной словоформе, местоимение «она» и «он» имеют по 7 и 8 словоформ соответственно (она, её, ей, ней, неё, нею, ею & он, его, ему, него, ним, им, нём, нему соответственно), слово «чувствительный» встретилось в 14 словоформах (чувствительный, чувствителен, чувствительные, чувствительной, чувствительного, чувствительная, чувствительную, чувствительно, чувствительнее, чувствительными, чувствительна, чувствительны, чувствительному, чувствительным) — сравнительные прилагательные часто имеют общие формы с наречием, а глаголы, которые имеют словоформы среди деепричастий и причастий, спрягаются по лицам, числу, соотносятся с разными временами лидируют в списке частоты встречаемости их словоформ: 1-е место занял глагол «занимать» — 81 словоформ, на 2-ом месте — «давать» — 74 словоформ; 3-е и 4-е места соответственно заняли глаголы «принимать» и «начинать» — по 69 и 68 словоформ соответственно.Вообще, первые три сотни мест занимают практически одни глаголы, а первое прилагательное («сильный») встретилось только на 283 месте. Ниже в таблице слева приведены первые 50 словоформ — как видим, это всё глаголы. Cправа представлены распределения словоформ.
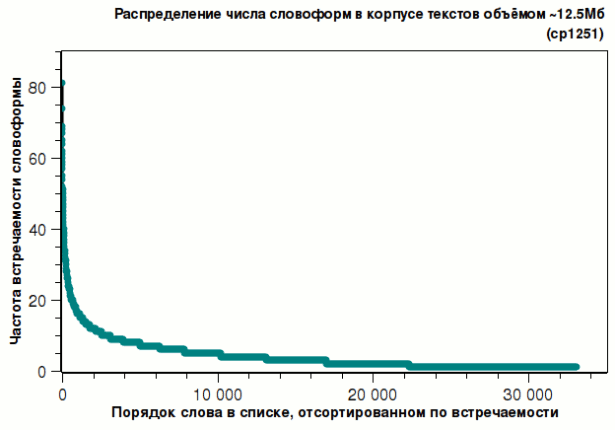
Если мы опять прологарифмируем обе оси, то прямую мы получим только для первой сотни глаголов, а далее производная будет спадать быстрее, чем линейно, хотя полученную кривую и можно будет аппроксимировать довольно неплохо большими отрезками прямых линий.
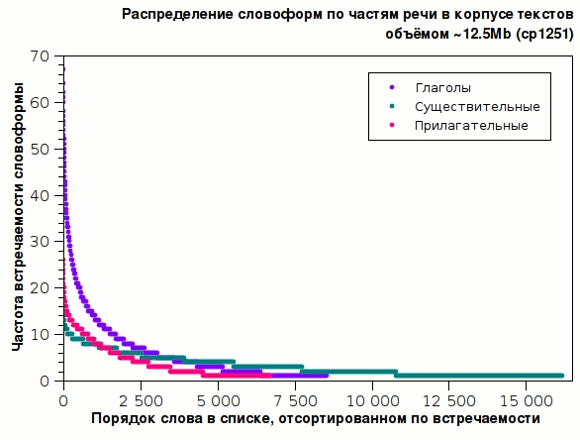
Распределение слов внутри частей речи, например глаголов, прилагательных и существительных ведёт себя уже скорее по экспоненциальному закону. При том слова, формирующие первые несколько сотен, хотя и являются наиболее употребимыми в основном, тем не менее, определяют стиль и даже эпоху текста. Например, в нашем корпусе текстов из русской и советской литературы первые 50 существительных выглядят вот так (в скобках указана частота встречаемости):
 Семантическая сеть на текстах русского языка
Посмотрим теперь на распределение связей слов в русском языке. Оно будет представлять из себя по виду такой же график, что и для распределения собственно слов:
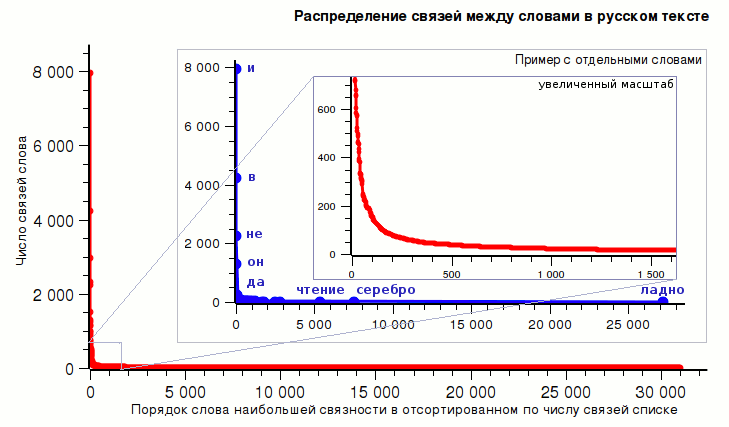
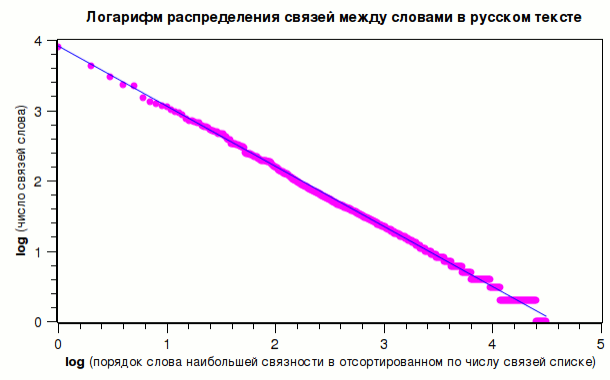
Взяв логарифм обеих осей, мы опять получим прямую на графике, что также доказывает степенной характер распределения связей между словами, и, таким образом, семантическая сеть русского языка получается немасштабируемой (scale-free). И даже более того: см. график выше, где синяя линия является аппроксимацией логарифмированного распределения связей в тексте на русском языке, всё того же объёма ~12.5Мб: семантическая сеть получается практически идеально немасштабируемой, т.е., вероятность того, что у случайно выбранного в тексте слова найдётся на весь этот текст k связей будет пропорциональна
Под связью между словами в данном анализе подразумевается сочетаемость слов, привидённых к неопределённой части речи. Т.е., количество связей между словами «белый» и «медведь» — это сколько раз встретилось по тексту их сочетание. Например, во фразе «Белый медведь объелся белым снегом» для «медведь» 2 связи, для «белый» — 3. При этом учитывается только то, как слова сочетаются в принципе: если в массиве текстов попадётся другая фраза со словосочетанием «белый медведь» (а мы это сочетание уже встретили ранее), то второй раз мы его не считаем. Т.о. на выбранный для анализа корпус текстов натягивается семантическая сеть. Если бы мне ранее не попадалась информация о том, что естественная английская речь может быть представлена немасштабируемой сетью, т.е. что слова и связи между ними распределены по одному и тому же степенному закону с близкими по значению показателями степени, то меня бы сильно удивили полученные результаты. Однако, одно то, что при логарифмировании кривой распределения связей между словами точки практически идеально уложились на прямую — это уже показалось мне достаточно поразительным результатом. ВыводыС помощью представленного способа анализа текстов можно составлять профили авторов и стилей для последующей их идентификации. Очевидно, что как общие распределения слов, так и по частям речи (особенно последние) будут отражать конкретные характеристики составленного текста, включая время написания, издание (литература, публицистика, новости, научная статья из той или иной области и т.п.), авторскую манеру. Так же интересно и перспективно было бы сравнить текстовые профили на разных языках, но одного периода и стиля издания — например, французскую и русскую литературу конца XIX века или топ-10 СМИ нашего времени в США, Англии, Китае и РФ — какие именно слова входят в первую сотню наиболее употребимых вообще и по частям речи, где те или иные случайно выбранные слова находятся в общем распределении.Более глубокие результаты подобного анализа можно также использовать для создания «умного» генератора фраз и робота-собеседника. Зная структуру семантической сети на «живом» тексте того или иного типа можно, видимо, определять автоматически стиль речи, нормируя её по зараннее разработанному профилю.
В процессе написания робота-генератора фраз использовалась также программа-парсер mystem, которая производит морфологический анализ текста на русском языке (автор — И. Сегалович, Yandex).
|